


Why KubeCarrier?
One of Kubernetes greatest – and most difficult to keep – promises is the ability to eliminate much of the operational burden of managing applications and services on multi-cloud infrastructure. Kubernetes Operators deliver on this promise by automating the management of applications and services lifecycle. However, provisioning, reconfiguring, and tearing down applications and services across multiple clusters is still hard and time-intensive.
With the power of Kubernetes Operators, it is easy to deploy and manage your applications with Kubernetes. However, there is no standard way and central management platform to provide your services and applications to people and make your applications accessible via a service catalog.
We believe that multi-cloud is the future, and managing services across multi-cloud infrastructure should be simple. IT people should focus on their core business or technical logic in the cloud-native fashion while leaving cross-cluster service management into safe and experienced hands. We can not find an existing project which meets our requirements. That’s why we built KubeCarrier, a generic solution to manage services on multi-cloud.
What Is KubeCarrier?
KubeCarrier is an open source project that addresses the complexities of automated full lifecycle management by harnessing the Kubernetes API and Operators into a central framework, allowing platform operators to deliver cloud native service management from one multi-cloud, multi-cluster hub.
KubeCarrier provides you:
- A central service hub to manage services across multi-cloud infrastructure
- Multi-tenancy and user management with access right controls, permissions, and policies to define quotas
Here is an example of how KubeCarrier delivers these features:
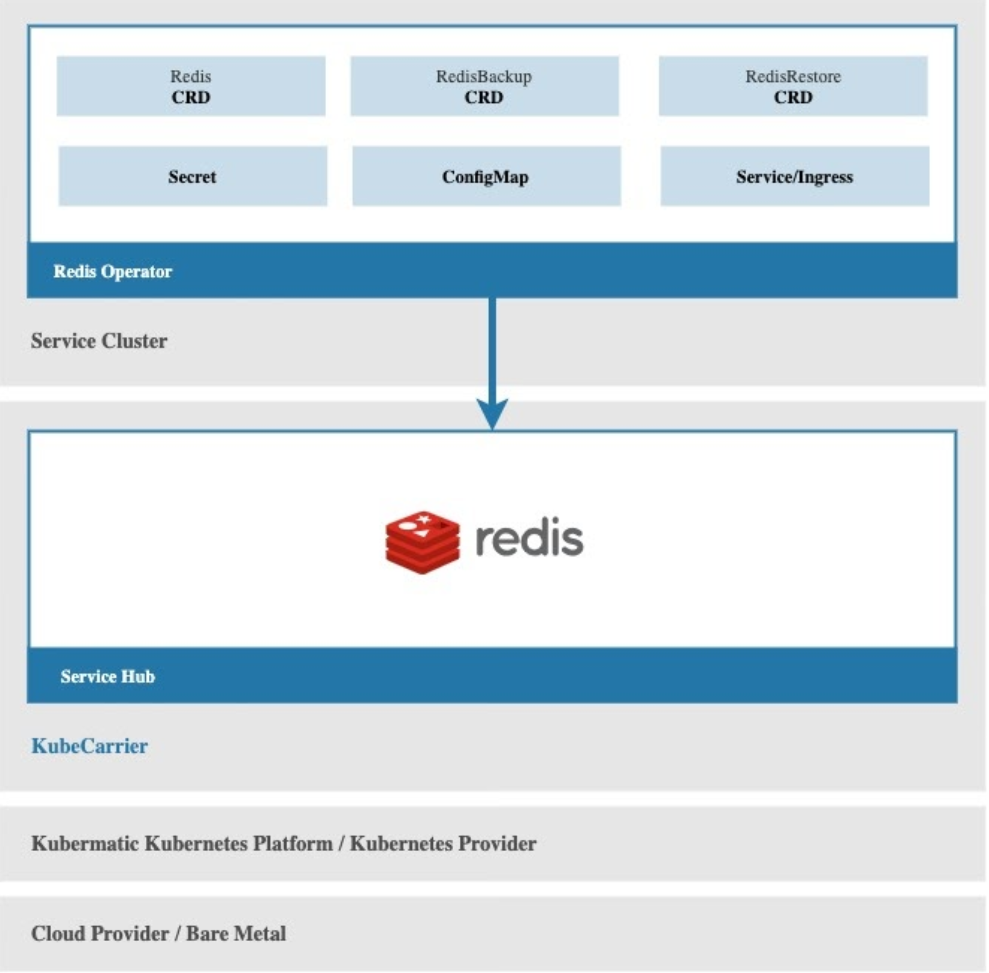
You have a redis operator running in your service cluster to provide redis database services, and there is a KubeCarrier installation running in a central management cluster. The only thing you need to do is to register your service cluster to KubeCarrier, and KubeCarrier will automatically discover the available redis services in the service cluster, and make them available in management and distribution in the central service hub.
Via the KubeCarrier service hub, your redis service will be available to users in KubeCarrier multi-tenancy environment, and you just lay back and leave service management into safe and experienced hands!
Overall:
- If you desire to share and provider your services to other people and organisations, but you don’t know where to make them accessible,
- If you want to use some reliable services instead of building everything yourself from scratch,
KubeCarrier service hub is definitely the right place to try!
Getting Started
In this guide, we will show you how to install KubeCarrier in Kubernetes, how to connect your first service cluster, and how to manage your first service via the KubeCarrier service hub.
Requirements
To install KubeCarrier, you need a Kubernetes Cluster with the cert-manager installed.
- Kubernetes: v1.16, v1.17, v1.18
- cert-manager: v0.14.0
Kubernetes Clusters
For the purposes of this tutorial, we are using kind - Kubernetes IN Docker as our Kubernetes cluster. In a production setup you might use Kubermatic Kubernetes Platform, or any other valid Kubernetes cluster provider.
# Management Cluster
$ kind create cluster --name=kubecarrier
Deploy cert-manager
# deploy cert-manager
$ kubectl apply -f https://github.com/jetstack/cert-manager/releases/download/v0.14.0/cert-manager.yaml
# wait for it to be ready (optional)
$ kubectl wait --for=condition=available deployment/cert-manager -n cert-manager --timeout=120s
$ kubectl wait --for=condition=available deployment/cert-manager-cainjector -n cert-manager --timeout=120s
$ kubectl wait --for=condition=available deployment/cert-manager-webhook -n cert-manager --timeout=120s
Installation
KubeCarrier is distributed via a public container registry: quay.io/kubecarrier. While the KubeCarrier installation is managed by the KubeCarrier operator, installing and upgrading the operator is done via our kubectl plugin.
This Command-line interface (CLI) tool will gain more utility functions as the project matures.
Install the Kubectl Plugin
To install the kubectl plugin, visit the KubeCarrier release page, download the archive and put the contained kubecarrier binary into your $PATH as kubectl-kubecarrier. You can also use it as a standalone binary without renaming it to kubectl plugin if preferable.
Make sure the binary is executable.
Check the KubeCarrier installer version:
$ kubectl kubecarrier version --full
Ensure you are running the latest release (the v0.3.0) with our up-to-date fixes, features, and security enhancement.
Install KubeCarrier
# make sure you are connected to the cluster,
# that you want to install KubeCarrier on
$ kubectl config current-context
kind-kubecarrier
# install KubeCarrier
$ kubectl kubecarrier setup
0.03s ✔ Create "kubecarrier-system" Namespace
0.19s ✔ Deploy KubeCarrier Operator
6.29s ✔ Deploy KubeCarrier
The kubectl kubecarrier setup command is idempotent, so if you encounter any error in your setup, it’s safe to re-run it multiple times.
API Access
KubeCarrier also deploys its own API Server to allow external access and integrations to connect with KubeCarrier. It is designed as a slim interface layer and all the heavy lifting (validation, authorization, etc.) is still done by Kubernetes Controllers, Kubernetes Admission Webhooks, and other Kubernetes mechanisms.
The KubeCarrier API Server supports multiple authentication methods. By default, kubectl kubecarrier setup starts the KubeCarrier API Server with ServiceAccount and Anonymous authentication methods enabled. KubeCarrier will also generate a self-signed certificate for localhost and 127.0.0.1 as a minimal TLS setup.
For more information, please refer to our official documentation, and see how to customize the KubeCarrier API server with different authentication methods and your own TLS setup.
Accounts
KubeCarrier manages everything in accounts and each account is separated by its own Namespace. Subjects within the Account get RBAC Roles set up and assigned, so they can interact with the system.
To start with KubeCarrier, we will create two accounts. The first account team-a, will provide services, while team-b will be able to consume services.
Each Account has a list of subjects, similar to RoleBinding objects. These subjects will be set up with admin rights for their namespace.
Accounts with the:
- Provider role can register ServiceCluster, manage Catalogs, and organize their services
- Tenant role can create services that were made available to them via Catalogs from a Provider
Accounts may be a Provider and a Tenant at the same time.
apiVersion: catalog.kubecarrier.io/v1alpha1
kind: Account
metadata:
name: team-a
spec:
metadata:
displayName: The A Team
description: In 1972, a crack commando unit was sent to...
roles:
- Provider
subjects:
- kind: User
name: hannibal
apiGroup: rbac.authorization.k8s.io
- kind: User
name: team-a-member
apiGroup: rbac.authorization.k8s.io
---
apiVersion: catalog.kubecarrier.io/v1alpha1
kind: Account
metadata:
name: team-b
spec:
roles:
- Tenant
subjects:
- kind: User
name: team-b-member
apiGroup: rbac.authorization.k8s.i
To create these objects, just run:
$ kubectl apply -f https://raw.githubusercontent.com/kubermatic/kubecarrier/v0.3.0/docs/manifests/accounts.yaml
After creating those accounts, you can check their status and namespace:
$ kubectl get account
NAME ACCOUNT NAMESPACE DISPLAY NAME STATUS AGE
team-a team-a The A Team Ready 7s
team-b team-b Ready 7s
Note: We will look more at the differences between the Provider and Tenant roles for accounts in our next blog about Service Hub With KubeCarrier.
Service Clusters
The next step is to register Kubernetes clusters into KubeCarrier. To begin, you need another Kubeconfig.
If you don’t have another Kubernetes cluster, go back to Requirements and create another cluster with Kind. In this example, we use the name eu-west-1 for this new cluster.
When you create another cluster with Kind, you have to work with the internal Kubeconfig of the cluster, using the following command:
$ kind get kubeconfig --internal --name eu-west-1 > /tmp/eu-west-1-kubeconfig
This will replace the default localhost:xxxx address with the container’s IP address, allowing KubeCarrier to talk with the other Kind cluster.
When creating a new cluster with kind your active context will be switched to the newly created cluster. Check kubectl config current-context and use kubectl config use-context to switch back to the right cluster.
To begin, you have to upload your Kubeconfig as a Secret into the Account Namespace.
$ kubectl create secret generic eu-west-1-kubeconfig \
-n team-a \
--from-file=kubeconfig=/tmp/eu-west-1-kubeconfig
Now that the credentials and connection information are in place, we can register the cluster into KubeCarrier.
apiVersion: kubecarrier.io/v1alpha1
kind: ServiceCluster
metadata:
name: eu-west-1
spec:
metadata:
displayName: EU West 1
kubeconfigSecret:
name: eu-west-1-kubeconfig
Create the object with:
$ kubectl apply -n team-a \
-f https://raw.githubusercontent.com/kubermatic/kubecarrier/v0.3.0/docs/manifests/servicecluster.yaml
$ kubectl get servicecluster -n team-a
NAME STATUS DISPLAY NAME KUBERNETES VERSION AGE
eu-west-1 Ready EU West 1 v1.18.0 8s
KubeCarrier will connect to the cluster, do basic health checking, and report the Kubernetes Version. Now, you have a service cluster that is connected to KubeCarrier!
Catalogs
CatalogEntrySet
In this chapter, we show how to manage your services across multiple service clusters via the KubeCarrier service hub.
To begin with, you need to have CustomResourceDefinitions (CRD) or operator installations in the service cluster. In this tutorial, we will use a CRD as an example.
Let’s register the example CRD in the service cluster that we created in the previous step.
Make sure you are connected to the service cluster:
$ kubectl config use-context kind-eu-west-1
Then register the CRD to the service cluster:
kubectl apply \
-f https://raw.githubusercontent.com/kubermatic/kubecarrier/v0.3.0/docs/manifests/couchdb.crd.yaml
Now, tell KubeCarrier to work with this CRD. For doing that, we create a CatalogEntrySet object in this example. This object describes which CRD should be fetched from which service cluster to the KubeCarrier central management cluster, and which fields will be available to users.
Here is an example:
apiVersion: catalog.kubecarrier.io/v1alpha1
kind: CatalogEntrySet
metadata:
name: couchdbs.eu-west-1
spec:
metadata:
displayName: CouchDB
description: The CouchDB database
discover:
crd:
name: couchdbs.couchdb.io
serviceClusterSelector: {}
derive:
expose:
- versions:
- v1alpha1
fields:
- jsonPath: .spec.username
- jsonPath: .spec.password
- jsonPath: .status.phase
- jsonPath: .status.fauxtonAddress
- jsonPath: .status.address
- jsonPath: .status.observedGeneration
Note: Don’t worry if you are not familiar with KubeCarrier objects! In our next blog, we will talk about Service Management with KubeCarrier in depth, and you can also find KubeCarrier API reference in our documentation website.
Then we switch to our central management cluster:
$ kubectl config use-context kind-kubecarrier
Create the CatalogEntrySet object above:
$ kubectl apply -n team-a \
-f https://raw.githubusercontent.com/kubermatic/kubecarrier/v0.3.0/docs/manifests/catalogentryset.yaml
Once the CatalogEntrySet object is ready, you will notice two new CRDs appearing in the management cluster:
$ kubectl get crd -l kubecarrier.io/origin-namespace=team-a
NAME CREATED AT
couchdbs.eu-west-1.team-a 2020-07-31T09:36:04Z
couchdbs.internal.eu-west-1.team-a 2020-07-31T09:35:50Z
The couchdbs.internal.eu-west-1.team-a CRD is just a copy of the CRD present in the ServiceCluster, while couchdbs.eu-west-1.team-a is a “slimmed-down” version, only containing fields specified in the CatalogEntrySet. Both CRDs are “namespaced” by their API group.
The CatalogEntrySet object we created in the previous step is managing CatalogEntry objects for service clusters that match the `serviceClusterSelector:
$ kubectl get catalogentry -n team-a
NAME STATUS BASE CRD TENANT CRD AGE
couchdbs.eu-west-1 Ready couchdbs.internal.eu-west-1.team-a couchdbs.eu-west-1.team-a 26s
We can now reference this CatalogEntry in a Catalog and offer it to Tenant!
For Every Account with the Tenant role, a Tenant object is created in each Provider namespace. In our example, Provider team-a can check Tenant in the system by:
$ kubectl get tenant -n team-a
NAME AGE
team-b 5m35s
Then team-a can offer the CouchDB CatalogEntry to Tenant team-b by creating the following Catalog object:
apiVersion: catalog.kubecarrier.io/v1alpha1
kind: Catalog
metadata:
name: default
spec:
# selects all the Tenants
tenantSelector: {}
# selects all the CatalogEntries
catalogEntrySelector: {}
$ kubectl apply -n team-a \
-f https://raw.githubusercontent.com/kubermatic/kubecarrier/v0.3.0/docs/manifests/catalog.yaml
When the Catalog is ready, selected tenants can discover objects available to them and RBAC is set up for users to work with the CRD in their namespace. Here we also use kubectl user impersonation (--as), to showcase RBAC:
# Offering objects contain information about CRDs that are shared to a Tenant.
# They contain all the information to validate and create new instances.
$ kubectl get offering -n team-b --as=team-b-member
NAME DISPLAY NAME PROVIDER AGE
couchdbs.eu-west-1.team-a CouchDB team-a 3m15s
# Region exposes information about the underlying Clusters.
$ kubectl get region -n team-b --as=team-b-member
NAME PROVIDER DISPLAY NAME AGE
eu-west-1.team-a team-a EU West 1 5m14s
# Provider exposes information about the Provider of an Offering.
$ kubectl get provider -n team-b --as=team-b-member
NAME DISPLAY NAME AGE
team-a The A Team 6m11s
First Service Instance!
Now, everything is set up! Time to create the first service instance. As team-b, we can create our first CouchDB object:
apiVersion: eu-west-1.team-a/v1alpha1
kind: CouchDB
metadata:
name: db1
spec:
username: hans
password: hans2000
kubectl apply -n team-b --as=team-b-member \
-f https://raw.githubusercontent.com/kubermatic/kubecarrier/v0.3.0/docs/manifests/couchdb.eu-west-1.yaml
Team-a is offering the CouchDB service from service cluster eu-west-1 and Team-b created an instance of the CouchDB service!
What’s Next?
In this guide, you have seen how simple it is to install KubeCarrier in a Kubernetes cluster, connect a service cluster, and manage a service via KubeCarrier service hub. In our next blog, we will show you more advanced features in depth about service management via KubeCarrier.
Learn More:
- KubeCarrier Documentation: https://docs.kubermatic.com/kubecarrier/v0.3/
- KubeCarrier Github Repository: https://github.com/kubermatic/kubecarrier

