


Edge computing is creating a new internet. In an age where consumers and businesses demand the shortest possible delay between asking a question and getting an answer, edge computing is the only way to reduce the time it takes to provide this insight. Edge computing shrinks the gap by lowering latency, dealing with data even when there is insufficient bandwidth, decreasing costs, and handling data sovereignty and compliance.
While centralized cloud computing will persist, the radically different way in which we can create and act upon data at the edge of the network will - and already does - create novel markets. By 2024, the global edge computing market is expected to be worth over $9.0 billion (USD) with a compound annual growth rate of 30%.
The key question is: what operational models and technologies will be able to effectively unlock this potential?
Kubernetes Unlocks Edge Computing
As a new field, edge computing is currently a blank slate with best practices still only emerging. Even without any standards in the field, many companies are starting to turn towards Kubernetes for their edge computing requirements.
Kubernetes has already taken enterprise IT by storm with 86% of companies using Kubernetes according to the latest Cloud Native Computing Foundation (CNCF) survey. While Kubernetes was born in the cloud, the benefits it provides also extend into the quickly emerging edge computing market.
With hardware and software spread across hundreds or thousands of locations, the only feasible way to manage these distributed systems is through standardization and automation enabled by cloud native technologies.
However, if companies truly want to use Kubernetes to manage their edge computing deployments, they must carefully consider the other challenges that the edge presents.
The top concern is resource constraints. Kubernetes was built in the cloud with almost infinite scaling capabilities. In contrast, edge computing usually has a very finite set of resources. The actual limitations can vary considerably from a few servers to a few hundred MBs of memory as we move from the regional edge to the device edge. However, they all share the restriction that every bit of overhead takes away from running actual applications.
With this in mind, the question now becomes: how can we reduce the footprint of Kubernetes to leave more space for customer applications?
The Smallest Kubernetes Cluster
A Kubernetes cluster consists of the control plane and the worker nodes. To shrink this footprint, some projects have tried to strip nonessential elements out of Kubernetes to create a slimmed down version.
However, this creates a fork of Kubernetes that needs to be maintained and managed independently from the rest of your Kubernetes stack. Instead of trying to cut things out, we can reimage how we architect our clusters to take into account how edge computing is architected.
Edge computing is not a precise place or type of device, but more a continuum of locations away from centralized cloud computing. Moving further away from the cloud usually means devices and bandwidth are more constrained.
However, each level of edge computing is usually connected back to, and to some extent controlled by, at least one of the levels above it. The edge is where the workload runs, but it still connects back to more centralized computing for higher level functions.
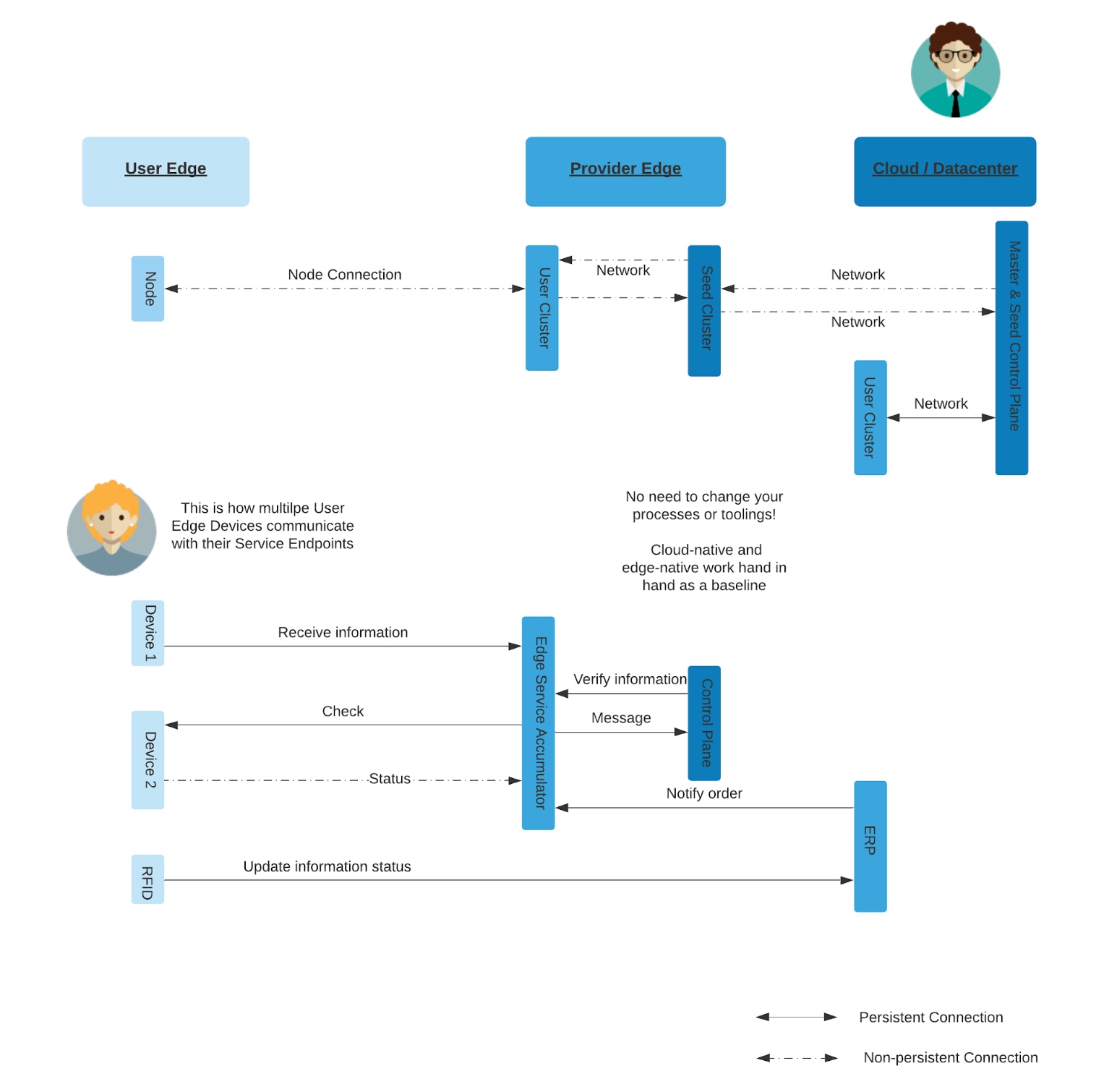
We can actually think of Kubernetes in the same way, as two independent parts: one centralized for control and one distributed for computing. The worker nodes run the applications while the control plane merely does the installation and maintenance of the workloads running in the cluster.
For a workload to just function, the control plane is not needed because it only does life cycle management. If the worker node loses connection to the control plane, the workloads can continue to function and run, they just will not be able to be updated.
With this in mind, we can think of the functional unit of our Kubernetes cluster as just the worker nodes with a kubelet. The centralized management of the control plane is not needed the whole time for the workload to be in working order.
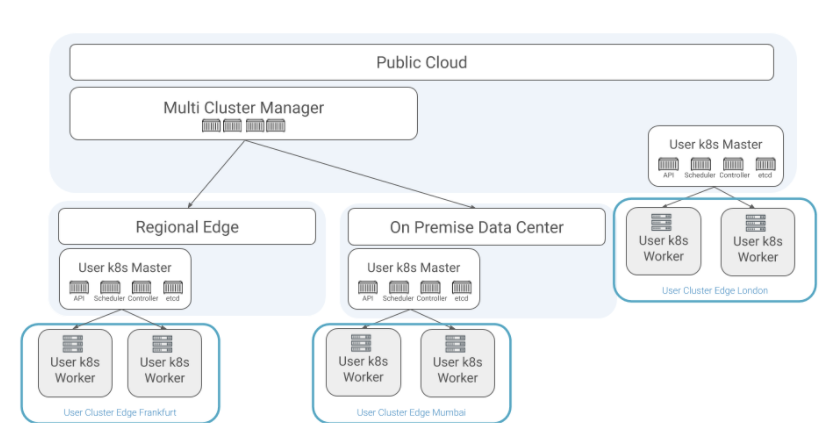
With this new concept of what a Kubernetes cluster really is, we can start to re-think how we build Kubernetes clusters for environments with limited resources. The worker nodes can be run on constrained devices while the control plane can be run in a more centralized location with additional resources, whether that be an on-premise data center or even extending back to the public cloud. This allows operations teams to run Kubernetes on edge computing without the need to make modifications or maintain another technology stack, all while minimizing overhead.
Cluster Management Chaos
The multi-billion dollar edge computing market will be composed of trillions of devices running millions of clusters. Thus, it begs the question of how to manage them and keep the control plane and worker nodes in sync even when they are running in separate locations.
We built the open source Kubermatic Kubernetes Platform with this use case in mind. Its Kubernetes in Kubernetes architecture already separates the control plane from the worker nodes and manages them independently. The control plane is run as a set of containers within another cluster that can be running in a less resource-constrained environment, while the worker nodes only need to run a kubelet, radically reducing the footprint of the Kubernetes cluster on the edge. In addition, Kubermatic Kubernetes Platform automates the cluster life cycle management which is especially important for edge computing business and operational models.
How to Try It Out
Kubermatic Kubernetes Platform allows users to separate the control plane and the worker nodes to run the smallest “Kubernetes clusters” for edge computing and constrained devices.
You can try it out for yourself or contribute to the project on GitHub.



